
The State of AI 2024
A Fundamental Analysis of AI Infrastructure, Applications, and Law


Welcome Note
Welcome to Revenant Research, hard research on the fundamentals driving AI from infrastructure to law. Revenant Research was born out of the internal need for me, and how I approach building AI software for regulated sectors. I began to immediately see a gap in AI research, which either focused on superficial trends or covered technical advancements in isolation. Revenant Research, I believe, is the first to connect infrastructure, applications, and law to build a fundamental picture of AI for regulated and critical sectors.
I decided to share the research. Along the way, I’ll share some of the background work in AI Agents and secure, enterprise-grade AI software Revenant is building, that is helping to create this corpus of research.
As of the this report Revenant research has produced over 80 audits on companie across the AI Supply Chain. We have tracked multiple court cases impacting AI, from IP to Fraud. Additionally, we have written over a dozen detailed primers on critical AI technologies and laws.
If you haven’t subscribed, or previously on Revenant’s email list, I encourage you to subscribe today.
Revenant will be putting out in depth research reports on critical areas of AI investment and opportunity for regulated and critical enterprises, from AI Insurance to Forensics, and M&A. Revenant provides clarity of fundamental AI factors transforming your business.
The State of AI 2024
Introduction
In recent years, artificial intelligence has evolved from an emerging technology to a transformative force. As enterprises look to invest, there’s a clear need for clarity on AI’s true capabilities, limitations, and the fundamental dynamics that will shape its trajectory. This research offers a first principles analysis, dissecting the enduring factors influencing the state of AI through three essential lenses: AI Infrastructure, AI Applications, and AI Regulation.
Infrastructure enables Applications: Improved infrastructure, like faster processors or better algorithms, directly expands the potential applications of AI. For example, without advancements in GPUs or TPUs, large language models and image generation models would be computationally infeasible.
Applications drive Infrastructure Demand: As AI applications grow, they often demand more specialized infrastructure (e.g., more data storage for generative AI models or more advanced sensors for autonomous vehicles).
Regulation affects both Infrastructure and Applications: Regulation can limit or accelerate the pace of infrastructure and application development. For instance, data privacy laws constrain how data can be used for training models, impacting both the quantity and type of data available.

Note: One gap I noticed that has been critical in my day job in the AI industry versus what is covered in research and podcasts is the lack of thorough analysis of AI law and regulation when examining the “AI stack”. It is often treated as a side conversation or discussion instead of a core lever in the advancement of AI. I think it’s because there are few of us who have a background in both. That gap has largely inspired Revenant Research.
Rather than focusing on fleeting trends, this examination highlights the core levers, or fundamental factors—both technological and regulatory—that underpin AI’s growth. For executives, primciples, policymakers, and investors, understanding these fundamentals are crucial for making decisions that align with the reality of AI's opportunities and constraints.
Trends create noise. Fundamentals create clarity.
Part 1: AI Infrastructure – Physical Limits and Technological Enablers
Fundamental Principle: Computation and data drive AI’s capability ceiling.
Projection: Hardware advancements are likely to continue, providing more computational power at lower energy costs. This will enable more complex and larger models, but also require massive energy and cooling resources. We may see a push toward sustainable AI infrastructure, potentially limiting exponential growth in model size.
Key Uncertainties: Physical and environmental limits on data centers, energy production and costs, and availability of rare materials.
AI infrastructure constitutes the foundation upon which all AI capabilities are built, encompassing compute power, data storage, energy, and scalable computing solutions. Each element within this infrastructure faces unique physical limits and dependencies that impact AI’s evolution.
Compute Power
AI’s computational capabilities rely heavily on advancements in semiconductor technology, particularly in specialized hardware like GPUs and TPUs. While these chips push the boundaries of processing power, fundamental physics imposes limits on miniaturization. As chips approach atomic scales (around 5nm and below), issues like electron leakage and heat dissipation emerge due to quantum mechanical effects, making it difficult to further shrink silicon-based transistors. Techniques such as 3D stacking and chiplet architectures are now used to overcome some of these limitations, extending the viability of silicon in the near term. However, these methods also face practical limits in efficiency and cooling as transistor density rises.
The industry’s leading hardware, such as NVIDIA's A100 GPU, offers substantial performance (e.g., 19.5 teraflops of FP32) but at high energy costs, highlighting an ongoing challenge: balancing power with performance. This challenge is amplified by costly manufacturing processes, such as EUV lithography, which require precision machinery and contribute to escalating production costs. As data centers adopt liquid and immersion cooling systems to manage heat, further innovation in energy-efficient processing becomes critical for sustainable AI development.
To meet future AI demands, researchers are exploring alternative architectures, including neuromorphic and quantum computing, which offer distinct advantages in specific applications. Neuromorphic chips, for instance, can efficiently handle real-time pattern recognition tasks, while quantum computing holds potential for optimization and cryptographic tasks. Although these technologies are nascent, their development alongside advancements in silicon-based approaches represents a more comprehensive path forward. By blending traditional and alternative architectures, the AI field can sustain performance gains while managing the costs and complexity of manufacturing at smaller scales.
Manufacturing Constraints and Future Supply Chain Risks
As AI technology and demand for high-performance hardware continue to expand, the manufacturing of semiconductors faces growing constraints linked to the supply of essential minerals. AI’s rapid development relies on a stable and scalable supply of minerals such as silicon, gallium, germanium, rare earth elements, lithium, cobalt, nickel, and copper—resources that underpin semiconductor and battery production. However, many of these minerals are primarily sourced from a limited number of countries, creating significant supply chain risks. These dependencies raise questions about whether the world’s mining output can meet the projected demand in the next decade as AI applications proliferate.
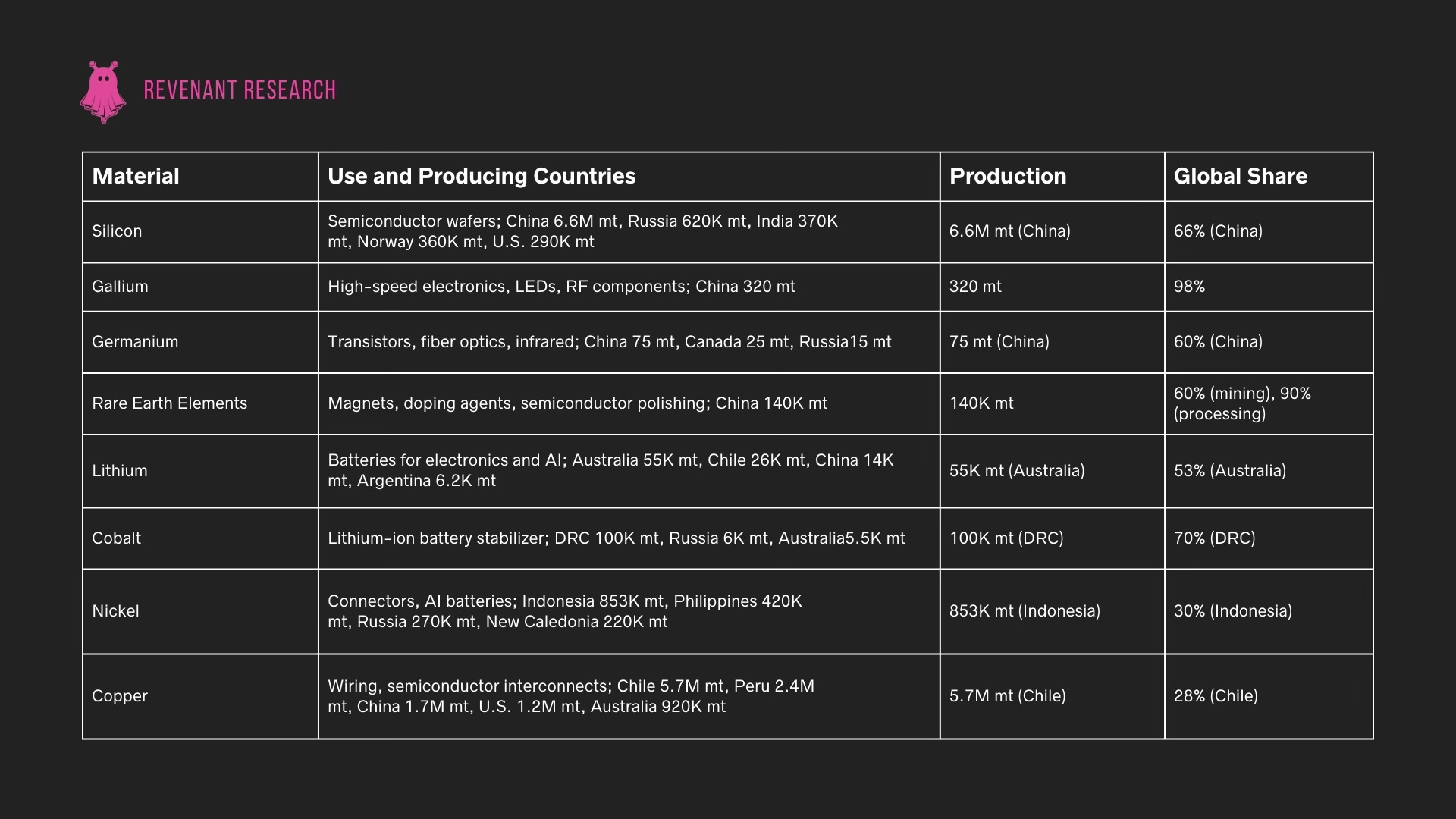
Global Mining Output and Production Concentration by Country
The supply chain is highly dependent on a few key minerals, with specific countries dominating their production. Current production data highlights the geopolitical concentration and strategic leverage held by a handful of nations:
Stockpile Reserves: U.S. vs. China
The disparity between the U.S. and China in terms of mineral reserves intensifies supply chain vulnerabilities. Stockpile data provides insight into the strategic leverage held by China in certain critical minerals:
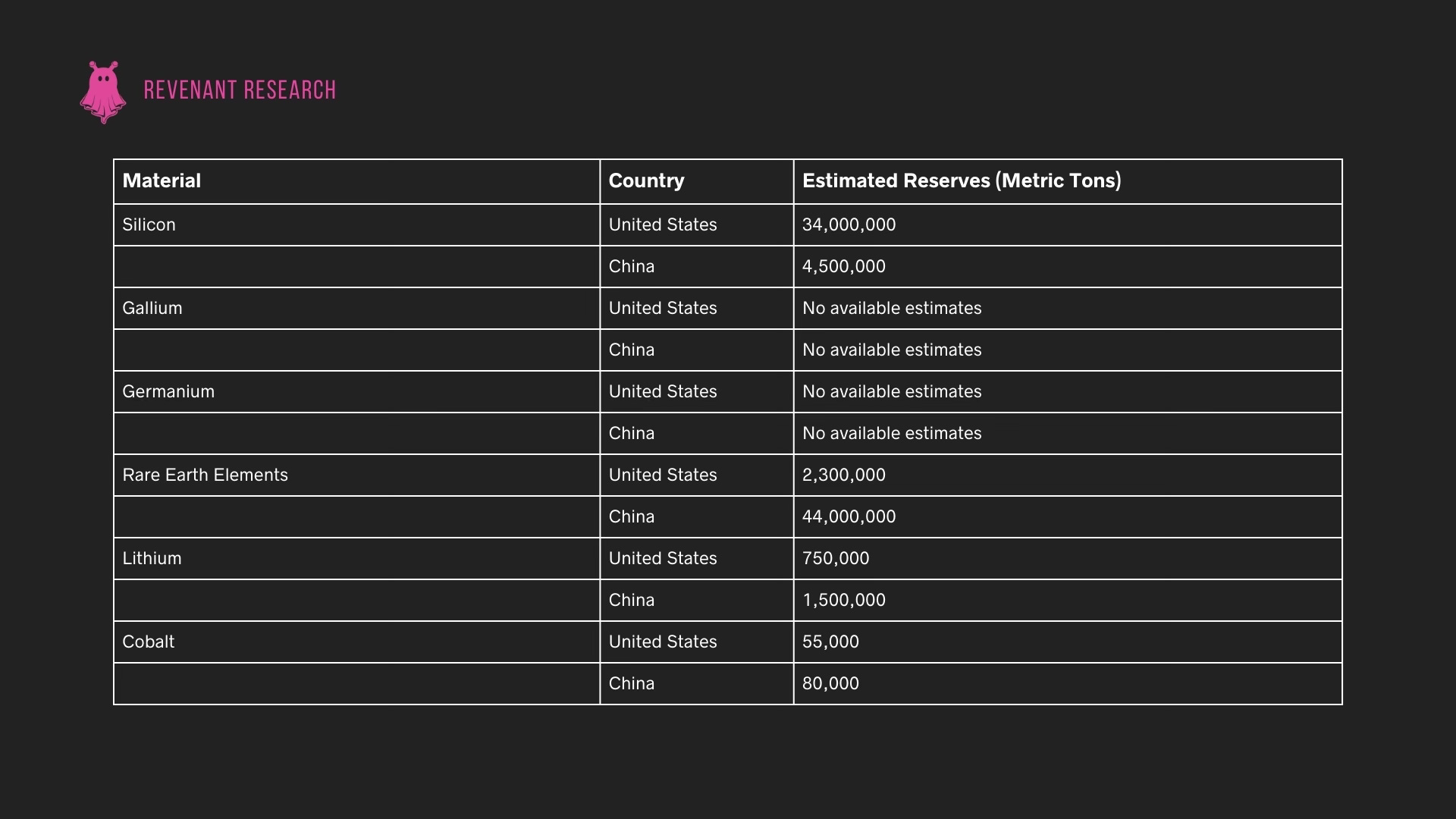
This data highlights China’s control over both current production and long-term reserves for several minerals essential to the AI and semiconductor industries. China’s 98% share of gallium production and its control of 60% of rare earth element mining (90% of processing) exemplify this leverage, as does its 44 million metric tons of rare earth reserves compared to the U.S.’s 2.3 million metric tons.
Constraints and Projected Demand for Key Minerals
AI infrastructure is fundamentally dependent on a set of critical minerals, each with unique constraints that influence scalability. Silicon underpins semiconductors and memory chips; however, the high-purity silicon required for advanced AI applications remains in limited supply due to specialized production facilities. This shortage could slow the production of AI processors, hindering overall growth in AI capabilities. Similarly, copper is essential for power and data transmission in AI data centers, but its supply is constrained by geographical concentration, primarily in Chile and Peru, and by environmental extraction challenges. Increasing global demand, driven by both AI infrastructure and broader electrification, places significant strain on copper availability, making it a potential bottleneck.
Rare earth elements, such as neodymium and dysprosium, provide essential magnetic properties for data storage. Their extraction, concentrated mainly in China, creates geopolitical risks and environmental concerns, particularly due to the high pollution associated with mining and refining. Lithium and cobalt are indispensable for energy storage in data centers and edge devices, but lithium extraction often depletes water resources in arid regions, while cobalt mining in the Congo raises ethical issues. Given the high projected demand for these minerals across AI, electric vehicles, and grid storage, recycling and efficient extraction technologies will be critical to meet growing needs sustainably.
Gallium and indium, critical for photonic and optical data transmission in AI infrastructure, are by-products of zinc and aluminum mining, which makes their supply indirectly dependent on other sectors. Limited recycling capabilities and high costs of production present additional challenges. Moving forward, AI infrastructure scalability will require innovative solutions, such as alternative materials, advancements in recycling, and diversified sourcing. Without these adaptations, the dependency on constrained mineral supplies could limit AI technology development, particularly as these materials face intensifying demand from interconnected sectors like telecommunications, IoT, and renewable energy.
Implications for AI Supply Chain Resilience
These constraints suggest that while the world’s mining output may partially meet AI-related demand over the next decade, supply chain vulnerabilities will likely persist, particularly for minerals like lithium, cobalt, gallium, and rare earth elements. Some key implications include:
Supply Disruptions and Price Volatility: Geopolitical tensions and environmental regulations could lead to supply disruptions or price increases for critical minerals, impacting the cost and availability of AI hardware.
Capacity Expansion Needs: Meeting projected AI demand will require increased mining capacity, especially in mineral-rich countries outside of China. However, the time and capital requirements for new mining projects mean that these sources may not come online quickly enough to meet short-term demand.
Strategic Dependence on China: China’s dominance in mineral production and processing, especially for rare earth elements and gallium, underscores the supply chain risks for other nations. For the U.S. and other tech-producing countries, this reliance highlights the need for resilient sourcing strategies to support sustained AI development.
Data Storage, Bandwidth, and Latency
As AI models grow in complexity and size, the data required to support them is expanding at an unprecedented rate, with the global datasphere projected to increase from 33 zettabytes in 2018 to 175 zettabytes by 2025. This growth presents a critical challenge for existing infrastructure, where the demands for storage capacity, bandwidth, and low latency must be balanced against physical, technical, and financial constraints. Meeting these demands will require a departure from traditional approaches in storage and networking, with a shift toward innovative solutions that can keep pace with AI’s rapid evolution.
Data storage lies at the heart of AI’s infrastructure requirements, as massive datasets fuel training and refinement processes. Cloud storage has become a mainstay for scaling data storage, but costs accumulate quickly at the petabyte scale. For example, as of 2023, Amazon’s S3 Standard storage costs $0.021 to $0.023 per gigabyte per month, and Google Cloud Storage’s standard tier is priced at $0.020 per gigabyte. For companies dealing with petabytes of data, this translates to monthly expenses in the tens of thousands, which has prompted exploration into alternatives that could offer better cost efficiency and storage density. Traditional storage mediums like hard disk drives and solid-state drives are nearing their physical limits in density and speed, meaning that current cloud costs will likely rise as data volumes increase. As a result, researchers are investigating high-density storage options such as DNA-based storage, which theoretically could store up to 215 petabytes in a single gram of material, and phase-change memory, which offers rapid data access. Although promising, these alternatives face technical and economic challenges. DNA storage, for instance, is highly durable but slow to retrieve data, making it better suited for archiving than real-time access, while phase-change memory remains prohibitively expensive at scale.
Beyond storage, bandwidth is a major concern for AI infrastructure, especially in applications that rely on real-time data processing. Fiber optic networks, widely used for high-speed data transmission, can deliver up to 100 gigabits per second in commercial settings, with experimental setups reaching as high as 319 terabits per second. Meanwhile, 5G networks, though promising theoretical peak speeds of up to 20 gigabits per second, typically deliver only 100 to 200 megabits per second under real-world conditions. As AI applications expand, especially in data-dense urban areas, these speeds are increasingly strained by network congestion, which can reduce effective bandwidth. Studies have shown that latency in urban networks can rise by as much as 20-30% during peak hours, limiting performance in latency-sensitive applications. To keep pace, network infrastructure will require substantial upgrades, and additional innovations such as decentralized data models may be essential.
Latency, or the time delay in data transmission, represents another crucial factor in AI infrastructure. Latency is bounded by physical limits—primarily the speed of light, which imposes a minimum delay of approximately five milliseconds per thousand kilometers traveled. For many applications requiring instantaneous processing, such as autonomous vehicles or financial trading systems, even small delays can be detrimental. Edge computing has emerged as a viable solution, processing data closer to its source to reduce transmission time. This localized approach has proven especially useful in minimizing latency for real-time AI applications and is projected to drive the edge computing market to $61.14 billion by 2028. However, while edge computing is highly effective in reducing latency for localized data processing, it cannot fully solve latency challenges for applications that involve long-distance data transmission. Supplementary approaches, such as software-defined networking (SDN) and content delivery networks (CDNs), are also being employed to address latency bottlenecks by optimizing data paths and caching data near end-users.
Recognizing these growing demands, the field is also moving toward more distributed and intelligent data management systems. Decentralized storage models like the InterPlanetary File System (IPFS) aim to address both latency and data accessibility by distributing data across a network of nodes, rather than relying on centralized data centers. By making data available at multiple geographic points, IPFS can reduce transmission delays, making it a compelling option for geographically distributed AI systems. However, while IPFS can improve availability and resilience, its retrieval times are not yet sufficient for dynamic, high-speed AI applications, limiting its current feasibility in scenarios that require instant data access.
Innovations in memory and compression technology are also helping to alleviate AI’s storage and transmission demands. Quantum memory, though still in experimental phases, holds the potential for ultra-dense data storage, offering rapid access times that could theoretically meet both storage and speed requirements for future AI infrastructure. Compression algorithms specifically tailored for AI data, such as Google’s BLADE, have achieved up to 60x compression without significant accuracy loss. This level of compression not only reduces storage demands but also decreases data transmission times, alleviating some bandwidth constraints in data-heavy applications. While compression technology helps streamline storage and transmission, it may also introduce slight processing delays, a factor to consider in latency-sensitive settings.
To optimize network resources, software-defined networking (SDN) provides dynamic allocation of network bandwidth, enabling high-priority data to bypass congested paths and improving efficiency for AI workloads. Similarly, content delivery networks (CDNs) cache frequently accessed data closer to end-users, reducing latency for applications that serve large user bases. For AI systems with global reach, CDNs help reduce transmission times and deliver a faster response to end-users, though they are generally most effective for semi-static content rather than real-time updates.
Ultimately, the challenges of data storage, bandwidth, and latency are deeply interconnected, and addressing one often impacts the others. A layered approach that combines multiple solutions offers the most robust path forward for AI infrastructure. Pairing edge computing with SDN and CDNs can create a comprehensive strategy for latency reduction, while decentralized storage systems and AI-driven compression techniques can alleviate the load on centralized data centers, enhancing both resilience and cost efficiency. These synergistic approaches ensure that data infrastructure can meet the vast demands of AI, especially in applications that require real-time responsiveness.
As AI models continue to grow in complexity, they will increasingly depend on a data infrastructure that can keep up not only in terms of processing power but also in efficient data storage, bandwidth management, and latency reduction. The interplay between these technologies—spanning traditional storage media, experimental storage models, and intelligent network management—will define the scalability of AI systems and their ability to meet next-generation requirements. A holistic, multi-layered approach to data infrastructure will be critical for the long-term success of AI applications in diverse, data-intensive fields.
Energy Supply and Efficiency
As AI technologies reach new heights in capability, the energy required to train and deploy large-scale models like GPT-4 presents serious challenges for sustainability and efficiency. AI models are growing rapidly in complexity and scope, driving exponential increases in power requirements and raising important environmental and economic considerations.
Training large language models is among the most energy-intensive processes in modern AI. To train GPT-4, OpenAI employed an estimated 25,000 NVIDIA A100 GPUs, running continuously for 90-100 days. The energy demands for this training process alone are staggering—estimated between 51,773 and 62,319 megawatt-hours (MWh), comparable to the annual electricity consumption of 5,000 to 6,000 average U.S. households. The cost of this computational effort is equally significant, with training expenses alone estimated at around $100 million. The location of training can also impact environmental outcomes: Training GPT-4 in a region like Northern Sweden, which relies on a cleaner energy mix, could equate to driving a car around the globe 300 times in terms of emissions. However, conducting the same training in a country with a higher fossil fuel dependency, like Germany, could amplify this footprint tenfold, underscoring the role of regional energy sources in AI’s environmental impact.
Energy demands don’t end with training; deploying or inferring from these models at scale also consumes substantial energy, especially for widely used applications like ChatGPT. In January 2023 alone, the energy consumption for ChatGPT’s inference processes equaled the monthly electricity use of 26,000 U.S. households. With an estimated 100 million active users, each request to GPT-4 represents a computational load that is ten times greater than its predecessor, GPT-3. If GPT-4 were adopted on a large scale, this could result in energy consumption of up to 91 gigawatt-hours (GWh) annually, nearly ten times the energy required by GPT-3, unless optimizations are made. Strategies such as model compression, parameter-efficient architectures, and deployment on specialized hardware could potentially reduce these operational energy costs, allowing models to serve large user bases without scaling energy demands linearly.
The extensive energy footprint of AI extends beyond individual models to the data centers that power them. Data centers are integral to AI infrastructure, currently consuming between 1-2% of global electricity—a figure expected to rise. In the United States, data center energy demands are projected to increase from 200 terawatt-hours (TWh) in 2022 to 260 TWh by 2026, or about 6% of the nation’s total energy use. Regional clusters of data centers, such as those in Northern Virginia, consume electricity equivalent to approximately 800,000 households. Such concentration creates unique challenges for power grids, as local surges in demand can strain energy infrastructure, particularly during peak hours. However, strategies like grid modernization and the integration of localized renewable energy sources, such as solar and wind, could mitigate these challenges and stabilize energy loads in regions with high data center density.
In response to these energy demands, the AI industry is exploring a range of solutions aimed at improving both energy efficiency and sustainability. On the technical front, research into optimized model architectures and more efficient training methods could significantly reduce energy requirements. For instance, approaches like model distillation and sparsity techniques allow large models to operate at lower computational loads without sacrificing performance. Meanwhile, investments in specialized AI hardware—such as TPUs and other performance-per-watt-optimized processors—are helping companies reduce the power consumption associated with training and inference.
Data centers are also adopting advanced cooling technologies to minimize the energy required for thermal management, which is a significant component of overall energy use. By deploying liquid cooling systems, data centers can reduce their reliance on traditional air conditioning, leading to more efficient power usage. Major technology firms are increasingly committing to renewable energy sources to offset their carbon footprint, using solar, wind, and even hydroelectric power to meet energy needs. Companies are also implementing “carbon-aware” computing practices, scheduling compute-intensive tasks for times when low-carbon electricity is more available, thereby reducing emissions associated with energy consumption.
Balancing AI’s computational growth with energy sustainability will require a multi-faceted approach, combining hardware innovation, software efficiency, and policy support. As AI becomes more embedded across industries and everyday life, ensuring its environmental sustainability will be critical for both economic viability and responsible development. Through continued advancements in efficiency, regional energy planning, and renewable integration, the AI sector can align its growth trajectory with a sustainable future.
Part 2: AI Applications – Practicality, Scalability, and Value Delivery
Fundamental Principle: AI applications mature when aligned with robust infrastructure and clear demand.
Projection: Some applications, like autonomous driving and personalized medicine, will likely see gradual improvements but remain constrained by regulatory and ethical challenges. Consumer and enterprise AI will likely continue expanding quickly, as the business incentives are strong and the regulatory landscape is more permissive.
Key Uncertainties: How quickly AI reaches human-level perception and decision-making for high-stakes applications (e.g., medicine and law) and the public’s trust in AI.
The true value of artificial intelligence lies in its applications—how it is used to reshape industries, streamline operations, and uncover new efficiencies. However, beyond AI's remarkable capabilities, success requires addressing the fundamentals of practicality and scalability. The impact of AI applications is largely determined by a few critical levers: model architecture, domain-specific viability, data availability, and user-centered design. Each of these elements not only sets the limits of AI’s effectiveness but also shapes the strategies that enterprises must adopt to make AI a viable and sustainable asset.
Model Architecture and Size
The evolution of artificial intelligence has been marked by a rapid increase in model size and complexity, with models like OpenAI’s GPT-4 containing over a trillion parameters. These expansive architectures represent a new level of computational capability, enabling models to generalize across diverse tasks and tackle challenges previously handled by multiple specialized systems. However, this rise in scale has come at significant cost, both financially and environmentally. Training GPT-3, a model with 175 billion parameters, cost an estimated $4.6 million; GPT-4, with its much larger architecture, required even more extensive resources, with training costs estimated around $63 million.
Despite the allure of larger models, scaling size alone offers diminishing returns. Research indicates that as models grow, the gains in accuracy decrease substantially; beyond a certain point, improvements often fall below 2%. Meanwhile, the computational demands—and associated costs—continue to rise. This trend reveals a critical insight: the objective is not to build the largest possible model, but rather the most effective model for a given task. Efficiency-focused architectures can achieve high levels of performance without the need for exponential increases in size.
The accelerating growth in model parameters is also outpacing hardware advancements, creating an imbalance where each new model generation requires disproportionately more resources. While GPUs, TPUs, and optimized algorithms provide incremental efficiency gains of 1.5x to 2x, model size often grows by multiples of 10 or more. This discrepancy results in sharply rising energy and compute costs, as training massive models demands not only high power consumption but also extensive cooling and infrastructure support. Although large models deliver advanced capabilities, the diminishing returns on performance gains make the costs—and environmental impact—significant challenges for AI scalability.
In response to these constraints, the field is exploring innovative model architectures and hardware solutions aimed at enhancing efficiency without sacrificing performance. Task-specific and sparse architectures are emerging as alternatives to brute-force scaling, where only the most relevant portions of a model are activated for specific tasks. Such architectures reduce the operational costs of inference, allowing models to maintain high accuracy without the resource demands of a trillion-parameter structure. Research into model distillation and transfer learning further supports this approach, enabling large models to “teach” smaller ones that can perform targeted functions with minimal computational overhead.
At the same time, advancements in AI-specific hardware offer promising avenues for improving the power efficiency of large models. Neuromorphic processors, designed to mimic the structure of the human brain, hold the potential for significantly reduced energy usage in AI tasks, while application-specific integrated circuits (ASICs) allow for energy optimization tailored to individual models. By shifting from general-purpose GPUs to specialized hardware, AI systems could achieve substantial efficiency gains, potentially offsetting some of the environmental and financial costs associated with large-scale models.
Ultimately, the path forward for AI will balance the quest for capability with the need for efficiency. As AI models continue to expand in complexity, the industry is increasingly focused on developing architectures and hardware that enable growth without unsustainable scaling in energy and costs. By prioritizing task-specific designs, leveraging new hardware, and focusing on scalable, efficient solutions, the AI field can advance in a way that aligns with both performance goals and environmental responsibility.
Rising Power and Versatility of Foundational Models Point Toward a Potential Consolidation in the AI Application Market
The rapid expansion of foundational models, with their ever-growing parameter counts and cross-domain versatility, is driving a shift in the AI application landscape. As these models scale in both capability and cost, the AI market shows signs of consolidation around a few key providers. The escalating expenses associated with multi-trillion parameter models, combined with their adaptability across diverse fields, suggest that foundational models may increasingly serve as comprehensive solutions, reducing the need for niche AI applications and specialized software providers.
The costs associated with training and accessing foundational models have soared in recent years. While training GPT-3 came with an estimated $4.6 million price tag, GPT-4’s trillion-parameter structure pushed costs above $60 million. The anticipated cost for future models, such as a hypothetical GPT-5, could reach hundreds of millions of dollars, as each parameter added compounds computational and energy demands. These high training costs are also reflected in the pricing for foundational model APIs, with GPT-4’s API offered at a higher rate than GPT-3 to offset these expenses. This cost structure has significant implications for companies building on top of these models, especially those with high usage volumes, as smaller or niche providers may struggle to absorb such rising expenses. Even large organizations may begin to weigh the costs and consider alternative solutions if API expenses continue to climb.
Beyond cost considerations, foundational models’ increasing sophistication across domains drives their appeal as general-purpose solutions. GPT-4, for instance, demonstrated near-expert-level performance in specialized fields, scoring in the top 10% on the bar exam and achieving similarly high scores on medical board examinations. This versatility means that foundational models can now undertake tasks once reserved for specialized AI, such as legal analysis, financial forecasting, and diagnostic assessments. As foundational models evolve, companies may find it more efficient to rely on a single model that performs well across multiple domains, rather than maintaining an assortment of specialized tools. This trend weakens demand for niche applications as businesses consolidate their AI infrastructure around multifunctional models, simplifying operations and potentially lowering total costs.
However, this consolidation dynamic has unique implications for smaller companies that have traditionally developed domain-specific applications. Many niche providers are now at risk of being outcompeted by foundational models, which are primarily available through large cloud platforms like Microsoft Azure, Google Cloud, and Amazon Web Services. Yet, these companies may adapt by layering proprietary data, regulatory compliance features, or industry-specific functionalities on top of foundational models. For example, in regulated fields like healthcare, where compliance with standards such as HIPAA is crucial, applications that incorporate specialized data or adhere to strict regulations may still retain a competitive edge. These adaptations allow niche providers to enhance foundational models in ways that address specific customer needs and regulatory requirements.
Scalability challenges also reinforce consolidation pressures, as the infrastructure and hardware requirements for multi-trillion parameter models create barriers that only a few large companies can overcome. Despite recent advances in GPU technology, such as the 4x efficiency gains of NVIDIA’s H100, these improvements lag behind the exponential increases in model size. The marginal cost reductions from hardware efficiency gains cannot fully counterbalance the rising expenses associated with training and deploying models at this scale, limiting the ability of smaller providers to compete on equal footing with industry giants.
The operational efficiency provided by foundational models further encourages market consolidation, as companies increasingly opt for centralized AI solutions that streamline infrastructure and reduce complexity. By relying on a single, versatile model, businesses can consolidate customer service, legal compliance, and analytics functions within one system, minimizing integration costs and simplifying maintenance. This shift toward consolidated AI stacks poses challenges for niche providers, as businesses gravitate toward fewer, multifunctional platforms that reduce the need for standalone applications. However, in highly specialized or regulated markets, niche software may still find demand, as foundational models alone may not meet the compliance or proprietary data needs of these sectors.
While market consolidation presents challenges for smaller providers, it also has benefits. Foundational models bring advanced AI capabilities to more companies, offering standardized quality and potentially driving down costs for end-users due to economies of scale. Yet, this trend may also reduce diversity and innovation, as fewer companies have the resources to develop competing solutions. With foundational models dominating general-purpose applications, businesses could face limited customization options and potential reliance on a small set of API providers.
In summary, the convergence of rising training costs and the growing versatility of foundational models points toward a future AI market dominated by a few key providers. Foundational models’ broad capabilities diminish demand for niche applications, while the operational efficiency of a single-model approach incentivizes consolidation. Niche companies, however, can continue to play a role by focusing on hyper-specialization, regulatory compliance, or adding proprietary enhancements to foundational models. The industry will likely experience a mixed impact: increased access to high-quality AI for a broader audience, alongside potential reductions in market diversity and specialization.
Data Availability and Quality
Data is the foundation of any AI system, with model performance tightly linked to the volume, quality, and diversity of training data. In practice, gathering and maintaining high-quality datasets is one of the most time-consuming and expensive aspects of AI. In fact, data collection and labeling can account for up to 80% of a project’s budget, with significant costs associated with ensuring data accuracy and representativeness. The quality of data directly impacts a model’s ability to generalize across diverse scenarios, and any bias or deficiency in the dataset can lead to unreliable or even harmful outcomes.
Consider the example of labeled medical imaging data, where human experts must painstakingly annotate thousands of images to create a dataset that accurately reflects diverse patient demographics and conditions. This process can cost anywhere from $1 million to $5 million, depending on the volume and complexity of the data required. In regulated fields such as healthcare, this challenge is compounded by data privacy laws that restrict access to sensitive information, limiting the pool of available training data.
One way companies are addressing this constraint is through synthetic data generation. Synthetic data, artificially created to mimic real-world scenarios, allows companies to generate training data at a fraction of the cost while preserving privacy. In sectors like autonomous driving and healthcare, synthetic data has reduced data acquisition costs by up to 50% and has shown to maintain model performance levels comparable to real-world datasets. While synthetic data is not without its limitations—namely, the risk that it may not fully capture real-world variability—it provides a valuable alternative in data-restricted fields.
The underlying principle here is that data quality dictates model quality. AI systems are only as reliable as the data they are built on, and without robust datasets that reflect real-world diversity and complexity, models are likely to fall short of expectations. Enterprises must prioritize a structured data strategy that encompasses data governance, privacy compliance, and quality control. In industries where data privacy is heavily regulated, investing in privacy-preserving techniques like federated learning or synthetic data can extend data access without compromising compliance. Additionally, continuous audits and updates to datasets are essential to ensure that models remain accurate and relevant over time.
User-Centric Design and Interpretability
For AI to deliver real value, it must not only perform effectively but also be accessible and transparent to users. Trust is central to AI adoption, particularly in high-stakes areas like healthcare and finance, where model recommendations can have significant impacts. However, deep learning models, often described as “black boxes,” pose a challenge to trust, as users are hesitant to rely on systems they cannot understand. This opacity can hinder the adoption of AI in sensitive domains where transparency and accountability are paramount.
Studies highlight this need for clarity, with 73% of users reporting a greater likelihood to trust AI if they understand how it makes decisions. Tools such as LIME (Local Interpretable Model-Agnostic Explanations) and SHAP (SHapley Additive exPlanations) have been developed to make complex model outputs more interpretable, offering users insight into how specific decisions are reached. By translating intricate model behaviors into understandable terms, these techniques help address compliance requirements in sectors with strict transparency standards, such as the European Union’s GDPR, which mandates that automated decisions be explainable.
However, scaling these interpretability tools to large language models (LLMs) like GPT-4, with billions or trillions of parameters, presents significant challenges. Methods like LIME and SHAP, designed initially for smaller models, struggle with the vast parameter space and the nuanced, context-sensitive processing that defines LLMs. These traditional techniques can be computationally prohibitive when applied to LLMs and may yield inconsistent insights. The sheer size of these models, coupled with their complex, non-linear interactions and reliance on long-range dependencies, complicates the use of perturbation-based approaches. To address this, researchers are developing alternative methods tailored to the unique demands of LLMs. Techniques such as attention visualization, probing tasks, and adapted versions of layer-wise relevance propagation are emerging as promising solutions. These new approaches aim to demystify LLM outputs by identifying patterns and feature relevance without succumbing to the limitations of conventional interpretability methods.
The demand for explainable AI is rising, driven not only by regulatory pressures but also by practical and ethical needs. Organizations increasingly seek interpretability to foster stakeholder trust, ensure compliance, and improve AI’s alignment with operational goals. In industries such as finance, healthcare, and criminal justice, explainability is vital, as decisions can have serious consequences for individuals and society. Technology research firms now identify AI governance and explainability as strategic priorities, reflecting the importance of understanding and interpreting AI-driven outcomes. In these high-stakes sectors, transparency serves as a foundation for responsible AI deployment, reinforcing accountability and supporting decision quality.
This shift toward transparency is not solely about meeting regulatory requirements—it is also a core component of responsible AI practice. Organizations recognize that explainability contributes to risk mitigation, fairness, and accountability, establishing a more robust framework for AI implementation. As such, there is a growing market for tools and methodologies that bring interpretability to complex models, allowing both technical and non-technical users to understand model behavior. This trend toward user-centric design will continue to influence AI development, positioning transparency as an essential feature of enterprise AI systems.
As the field of AI advances, interpretability is increasingly seen not as an optional add-on but as a core requirement for AI applications in enterprise and high-stakes environments. With demand for explainable AI expected to shape future AI systems, transparency will become essential for organizations looking to harness AI responsibly and effectively. Through interpretability, AI can fulfill its promise of providing high-impact, trustworthy solutions that empower users, build confidence, and support informed decision-making.
Part 3: AI Regulation – Governance, Compliance, and Ethical Standards
Fundamental Principle: Regulation seeks to balance innovation with ethical, safety, and societal stability concerns.
Projection: Regulation will likely become stricter as AI systems gain more autonomy and influence over sensitive areas like healthcare, finance, and law. However, some regions may adopt a more permissive regulatory stance to encourage AI development and economic competitiveness, creating a fragmented regulatory environment.
Key Uncertainties: The possibility of international regulatory standards, similar to climate or trade agreements, and the emergence of ethical AI standards in countries with differing governance philosophies.
As artificial intelligence becomes embedded in society’s most critical systems—from healthcare to finance to law—regulation has become both a foundational requirement and a complex challenge. Unlike traditional software, AI introduces autonomous decision-making into high-stakes environments, raising unprecedented questions about ethics, accountability, and security. Regulatory bodies are addressing these concerns by establishing standards around data privacy and security, transparency and explainability, accountability and liability, and global regulatory coordination. Each of these areas represents both a regulatory necessity and a competitive opportunity for enterprises, as organizations that align with ethical AI practices stand to gain user trust and regulatory favor.
Privacy and Data Security
In the era of AI, data fuels insights and enables intelligent automation, but this dependency also brings significant privacy and security concerns. Laws like the General Data Protection Regulation (GDPR) in the EU and the California Consumer Privacy Act (CCPA) in the U.S. impose strict requirements on how personal data is managed, processed, and stored. Non-compliance with GDPR alone has led to over €275 million in fines, underscoring the high stakes for companies operating in data-sensitive industries. Beyond compliance, these regulations reflect a broader demand for privacy that has become essential to building public trust.
Consumer expectations around privacy have evolved significantly, with growing awareness and concern over how personal data is used. According to a 2022 KPMG survey, 86% of respondents expressed rising concerns about data privacy, while 78% reported fears about the sheer volume of data being collected. In response, organizations are increasingly adopting privacy-preserving techniques like differential privacy, which introduces controlled noise into datasets to protect individual identities while preserving overall data utility. While differential privacy offers significant protection, it also introduces trade-offs between privacy and data accuracy. Depending on how it is applied, these trade-offs can range from minimal impacts to more substantial reductions in data utility, requiring organizations to carefully balance the level of privacy against model performance. As regulations continue to tighten and consumer awareness grows, businesses must navigate this balance with precision, aiming to meet both privacy expectations and analytical needs.
Federated learning has emerged as another powerful tool for enhancing privacy. This technique allows models to train across decentralized data sources without moving data to a central server, preserving privacy while enabling large-scale AI applications. Federated learning is especially valuable in highly regulated fields like healthcare, where data privacy is critical, yet access to diverse datasets is necessary for effective model outcomes. By keeping data local, federated learning enables models to learn from geographically or institutionally distributed sources without exposing sensitive information, minimizing the risk of data breaches or misuse. However, federated learning is not without its own challenges; it can be vulnerable to security risks, such as model inversion attacks, where an adversary could potentially infer private information from model updates. As a result, federated learning is most effective when implemented alongside robust security practices, such as encryption and rigorous access controls.
Balancing privacy and data utility is a complex task, but advancements in privacy-preserving AI are helping organizations manage this trade-off more effectively. Innovations in adaptive privacy techniques, for example, allow organizations to adjust the level of privacy protection based on the context and data sensitivity, minimizing accuracy loss in critical applications. By selectively applying privacy measures, companies can better preserve data utility while still adhering to stringent privacy standards. This adaptability is particularly valuable in applications where precision is essential, such as in healthcare diagnostics or financial forecasting, where even small data inaccuracies can significantly affect outcomes.
In addition to technical measures, transparency and proactive communication are essential for building user trust. Today’s consumers expect more than regulatory compliance; they want to understand how their data is collected, used, and protected. Proactive transparency—clearly explaining data practices and privacy protections—helps to reassure users and fosters a stronger relationship of trust. This shift toward transparency is not only about meeting legal requirements but also about addressing the ethical and practical expectations of privacy-conscious consumers.
In an AI-driven world, privacy and data security strategies are evolving to meet both regulatory requirements and consumer demands. Privacy-preserving techniques like differential privacy and federated learning offer powerful safeguards, but they are most effective as part of a comprehensive security approach that includes encryption, access control, and continuous monitoring. As privacy technologies advance, organizations can achieve a better balance between protecting individual data and maintaining high data utility. Meanwhile, proactive communication about privacy practices strengthens consumer trust, creating a foundation for responsible and sustainable AI use. By integrating robust privacy protections with transparent practices, organizations can not only meet compliance standards but also build a resilient, trust-driven relationship with their users.
Transparency and Explainability
The exponential growth in the size and complexity of AI models, particularly large language models with billions to trillions of parameters, has created a fundamental challenge to the traditional notions of AI transparency and explainability. As these models achieve unprecedented capabilities in natural language processing and generation, they have also become essentially impenetrable "black boxes," defying conventional methods of interpretation and explanation. This opacity is not a mere inconvenience; it represents a paradigm shift that strikes at the heart of current regulatory approaches and ethical guidelines for AI. The reality is that as models like GPT-4, Llama 3 and their successors grow in size and capability, the goal of true transparency – understanding the specific reasoning behind each output – becomes increasingly unattainable. Traditional explainability techniques such as LIME (Local Interpretable Model-Agnostic Explanations) and SHAP (SHapley Additive exPlanations), while valuable for simpler models, are computationally infeasible and often meaningless when applied to these massive neural networks. The sheer number of parameters and the complexity of their interactions make it impossible to trace the exact path from input to output in a way that humans can comprehend.
This technological reality clashes directly with the growing demand for AI accountability, especially in high-stakes applications that impact individual rights and societal wellbeing. Regulatory frameworks, such as the EU's proposed AI Act, often assume a level of transparency that is no longer technically achievable with these advanced models. Given this fundamental disconnect, we must radically reconsider our approach to AI governance:
Shift from internal transparency to outcome-based evaluation: Instead of futilely attempting to explain the internal workings of these models, focus on rigorous testing of outputs across a wide range of scenarios.
Develop new metrics for trustworthiness: Create standards for evaluating model reliability, bias, and safety that don't rely on understanding internal processes but instead focus on consistent performance and alignment with human values.
Emphasize process transparency: While the model itself may be opaque, the processes around its development, training data selection, and deployment can and should be made more transparent.
Implement robust testing and monitoring frameworks: Develop comprehensive systems for continuous evaluation of AI outputs in real-world applications, allowing for rapid intervention if issues arise.
Redefine explainability for different stakeholders: Recognize that different levels of explanation are needed for different audiences (e.g., regulators, users, affected individuals) and develop appropriate frameworks for each.
Invest in AI literacy: Improve public understanding of AI capabilities and limitations, fostering more nuanced societal expectations and oversight.
This shift in perspective acknowledges the technical limitations imposed by the scale of modern AI systems while still striving to ensure these powerful technologies remain aligned with societal values and subject to meaningful oversight. It requires a collaborative effort between AI researchers, ethicists, policymakers, and industry leaders to develop new paradigms of accountability that are suitable for the age of large foundational models. As we navigate this new landscape, we must remain adaptable, continuously reassessing our approaches as AI technology evolves. The challenge of governing increasingly opaque AI systems is not a problem to be solved once, but an ongoing process of innovation, evaluation, and ethical consideration. Our goal must be to harness the immense potential of these advanced AI models while developing novel, effective means of ensuring their responsible development and deployment.
Accountability and Liability
As AI systems become increasingly autonomous and complex, traditional notions of liability and accountability are being challenged. According to the Cornerstone Research and Stanford Law School Securities Class Action Clearinghouse report, there were 6 Artificial Intelligence (AI) trend category filings in the first half of 2024, indicating a growing focus on AI-related securities litigation in the U.S. federal and state courts. High-stakes fields such as healthcare, finance, and criminal justice are particularly vulnerable, as evidenced by cases like the 2019 class-action lawsuit against UnitedHealth Group alleging discrimination by an AI algorithm.
Regulators are responding with more stringent accountability requirements, exemplified by the EU's proposed AI Act. However, traditional approaches like "Human in the Loop" (HITL) systems can inadvertently shift liability to human operators who may not fully understand complex AI systems, especially given their often opaque nature.
To address these challenges, a fundamental reconceptualization of AI liability and accountability should be considered:
Outcome-Based Liability: Shift focus to the real-world impacts of AI systems rather than their internal workings or individual human responsibility.
Strict Liability for High-Risk Applications: Implement a strict liability regime in sectors where AI decisions significantly impact human lives or rights, making organizations responsible for any harm caused, regardless of fault.
Mandatory Insurance: Require organizations deploying high-risk AI applications to carry specialized AI liability insurance, ensuring compensation for affected individuals and creating a market mechanism for assessing AI risks.
Regulatory Oversight: Establish a dedicated AI regulatory body with technical expertise to set and enforce standards, conduct audits, and suspend or ban harmful AI systems.
Enhanced Transparency Requirements: Mandate comprehensive, accessible records of AI development, testing, and performance, including training data sources, known limitations, and real-world performance metrics.
Legal Recognition of AI Agency: Develop new legal frameworks that recognize the unique nature of AI decision-making, potentially establishing AI systems as distinct legal entities in certain contexts.
International Harmonization: Work towards global standards for AI liability and accountability to prevent regulatory arbitrage and ensure consistent protection across jurisdictions.
This approach acknowledges the inadequacy of traditional oversight methods for complex AI systems and instead focuses on creating systemic safeguards and clear lines of responsibility. It incentivizes rigorous testing and monitoring, encourages responsible AI deployment, and provides clearer paths to redress for individuals harmed by AI decisions.
Implementing this framework will require significant legal and regulatory changes, as well as industry cooperation. However, as AI continues to permeate critical aspects of society, such bold steps are necessary to ensure that the benefits of AI can be realized while effectively managing its risks and providing just recourse when harms occur.
Global Regulatory Coordination for AI
The fundamental challenge in regulating AI globally stems from the inherent tension between the borderless nature of AI technology and the fragmented landscape of national regulations. This tension creates significant inefficiencies and risks:
Regulatory Fragmentation: While AI development and deployment occur globally, regulatory approaches vary widely. The EU's AI Act emphasizes strict oversight and individual rights, while the US prioritizes innovation and industry self-regulation. This divergence reflects differing values, legal traditions, and economic priorities.
Compliance Burden: Multinational organizations face substantial costs and operational challenges in navigating conflicting regulatory requirements. The Digital Policy Alert has documented over 450 policy and enforcement developments targeting AI providers in the past year alone, illustrating the rapidly evolving and complex regulatory landscape.
Innovation Hindrance: Fragmented regulations can stifle innovation by creating uncertainty and increasing barriers to entry, especially for smaller companies and startups operating across borders.
Regulatory Arbitrage: Inconsistent global standards create opportunities for companies to exploit regulatory gaps, potentially undermining the effectiveness of AI governance efforts.
Regulatory Capture: The largest tech companies can deploy significant funding towards lobbying efforts to craft and shape regulation that is complex and costly, thereby strangling startups and smaller competitors.
To address these challenges, a robust and coordinated approach to global AI regulation is necessary:
Establish a Global AI Governance Body: Create an international organization with the authority to set binding global standards for AI development and deployment. This body should have representation from major AI-producing and consuming nations, technical expertise to assess and monitor AI systems, and enforcement mechanisms.
Implement a Tiered Regulatory Framework: Adopt a risk-based approach that categorizes AI applications based on their potential impact, with high-risk applications subject to strict global standards and lower-risk applications having more flexible oversight.
Develop a Global AI Registry: Create a centralized database of high-risk AI systems, including details on their purpose, training data, and known limitations to enhance transparency and facilitate coordinated oversight.
Foster International AI Research Collaboration: Establish a global AI research consortium to pool resources, share knowledge, and develop common standards for responsible AI development.
Create AI Ethics Tribunals: Establish international tribunals to adjudicate disputes and alleged violations of global AI standards, ensuring consistent interpretation and application of regulations across jurisdictions.
Harmonize Liability Frameworks: Develop a consistent approach to AI liability across jurisdictions, clarifying responsibility for AI-caused harms and ensuring adequate compensation mechanisms.
Implement a Global AI Incident Reporting System: Mandate reporting of significant AI failures or unintended consequences, facilitating rapid response and shared learning.
Enhance Regulatory Interoperability: While complete uniformity is unrealistic, governments should strive for regulatory interoperability. Initiatives like the crosswalk between Singapore's "AI Verify" and the US's "AI Risk Management Framework" serve as models for bridging varying regulatory environments.
Utilize Regulatory Sandboxes: Expand the use of regulatory sandboxes, similar to those implemented in the FinTech sector, to allow for controlled testing of AI technologies and inform more effective regulation.
Prioritize Capacity Building: Develop programs to enhance AI governance capabilities in developing nations, ensuring more equitable participation in global AI regulation.
Implementing this framework will require significant political will and international cooperation. However, given the potential risks and benefits of AI technology, a robust global governance structure is essential to harness its potential while mitigating its dangers. By adopting a coordinated, risk-based approach to AI regulation, we can foster innovation, ensure consistent protection for individuals, and build a foundation for responsible AI development on a global scale.
Conclusion
Strategic AI Adoption: Navigating Scenarios for Executives and Investors
As AI technology continues to advance, its adoption will be influenced by a complex interplay of infrastructure, applications, and regulation. Executives and investors should consider three potential scenarios: Regulated Growth with Sustainable AI Development, Rapid Expansion with Minimal Regulation, and Technological Stagnation due to Over-Regulation. Each scenario requires tailored strategies to balance risks, opportunities, and long-term resilience. This guide offers a nuanced analysis and specific recommendations for each scenario, emphasizing adaptability and strategic foresight.
Scenario 1: Regulated Growth with Sustainable AI Development
In this scenario, AI advances steadily, driven by a focus on sustainability and safety regulations. While innovation continues, companies must navigate stringent regulatory landscapes, particularly in areas like data privacy and AI ethics. Executives and investors should consider the following:
1. Infrastructure Investments
Energy Efficiency and Sustainability: Invest in energy-efficient models and eco-friendly data centers to meet both regulatory requirements and growing consumer demand for sustainable practices. Consider edge computingsolutions to reduce data transfer costs and energy consumption.
Data Compliance Systems: Prioritize building data governance frameworks that can adapt to shifting privacy laws, like GDPR or emerging standards. Focus on technologies such as differential privacy and federated learning to maintain competitive access to data while ensuring compliance.
2. Application Focus
High-Regulation Sectors: In fields like healthcare, finance, and automotive, the need for compliance will be critical. Invest early in regulatory expertise and auditability tools to enable safe deployment in these sectors.
Sustainable AI Solutions: Develop applications that align with corporate social responsibility (CSR) goals, such as environmental monitoring or resource optimization, which will resonate with stakeholders and align with regulatory standards.
3. Strategic Positioning
Engage with Regulators: Proactively collaborate with regulatory bodies and industry groups to influence emerging standards and ensure smoother product rollouts. This involvement can create a competitive advantage.
Long-Term Flexibility: Invest with a long-term perspective, emphasizing modular infrastructure and scalable AI solutions that can be adjusted as regulations evolve, ensuring adaptability in a dynamic regulatory environment.
For investors, companies with a strong focus on compliance, sustainable practices, and a long-term vision are well-positioned for steady growth in this scenario.
Scenario 2: Rapid Expansion with Minimal Regulation
This scenario envisions a fast-paced environment with few regulatory constraints, allowing companies to pursue aggressive innovation. However, competition is intense, and public backlash can arise if ethical considerations are overlooked. Strategic considerations include:
1. Infrastructure Investments
Scalable and Specialized Hardware: Invest in specialized AI hardware and cloud-based AI resources to handle increasing data and computational demands. Focus on high-throughput data pipelines for rapid model training and deployment.
Data Aggregation Strategies: Leverage more open data access to build comprehensive data management systems that can support diverse applications, from consumer personalization to complex enterprise models.
2. Application Focus
High-Growth, Consumer-Centric Applications: Prioritize AI solutions that drive customer engagement and personalization, such as recommendation systems, digital assistants, and predictive analytics for e-commerce.
Agile Development and Experimentation: With minimal barriers to deployment, emphasize rapid prototypingand iterative developmentto quickly capture market opportunities. Flexibility to pivot as market needs change is key.
3. Strategic Positioning
Differentiate Through Trust: Even in a low-regulation environment, building consumer trust can be a competitive advantage. Voluntarily adopting transparency measures around AI-driven decisions can preemptively address potential regulatory shifts.
Strategic Alliances: Collaborate with tech providers to share infrastructure and expertise, ensuring scalability without overextending on capital. Partnerships can also enable access to proprietary datasets and cutting-edge AI tools.
For investors, companies that can rapidly scale AI applicationswhile maintaining consumer trust and agility are likely to deliver high returns. Prioritize those that balance innovation with a preparedness for potential future regulations.
Scenario 3: Technological Stagnation due to Over-Regulation
In this scenario, heavy regulation creates high barriers to AI development, particularly around data usage and deployment in safety-critical sectors. Growth is constrained, and only low-risk or highly compliant applications can thrive. Executives and investors should adopt the following strategies:
1. Infrastructure Investments
Compliance-Focused Systems: Invest in secure data storage, advanced encryption, and privacy-preserving technologies like federated learning. These can support AI model training while navigating strict data laws.
Moderate Infrastructure Scaling: Avoid over-investing in cutting-edge AI infrastructure, as regulatory constraints may slow the return on such investments. Focus on scalable but adaptable systems that can adjust to evolving regulatory demands.
2. Application Focus
Low-Risk, Efficiency-Enhancing Applications: Focus on AI tools that improve internal processes and operations, such as business process automation or customer service chatbots, which face lower regulatory scrutiny.
Risk-Averse Sectors: Target applications that do not rely on highly sensitive data, such as predictive maintenancein manufacturing or automated quality control, which can enhance productivity with minimal regulatory hurdles.
3. Strategic Positioning
Leverage Compliance as a Strength: Develop a reputation for regulatory expertise and high compliance standards to attract partners and customers who seek safe, reliable AI solutions.
Lobbying and Policy Engagement: Engage actively in policy discussions to advocate for balanced regulations. Establishing a presence in industry standardization efforts can help shape a more favorable environment in the long term.
For investors, companies that specialize in privacy-enhancing technologies or focus on low-risk, high-compliance applications are likely to weather this environment best. Those with strong lobbying capabilities or a role in shaping regulatory standards could have a strategic edge.
General Strategic Takeaways Across Scenarios
Prepare for Hybrid Outcomes: Real-world scenarios may combine elements of these models, with varying regulations across regions and sectors. Companies should adopt flexible strategiesthat can adapt to different regulatory environments, focusing on scalable infrastructure and sector-specific compliance.
Focus on Long-Term Resilience: Prioritize infrastructure and application choices that remain adaptable to changing regulatory and market conditions. This includes modular AI architecture and investment in data governance frameworks that can be adjusted as laws evolve.
Proactive Ethics and Sustainability: Proactively integrating ethical considerations and sustainability into AI development can serve as a differentiator even in minimally regulated environments. This builds public trust and prepares companies for future regulatory shifts.
By aligning their strategies with these insights, executives and investors can navigate the evolving AI landscape with greater confidence. Emphasizing adaptability, ethical practices, and long-term resilience will help maximize value from AI investments, regardless of the specific regulatory or technological scenario that emerges.