
Introducing The AI Infrastructure Cycle
Revenant Research's framework for understanding AI Economics


As enterprises move from experimenting with AI to embedding it directly into critical operations, a new market is forming around the infrastructure that supports it. AI-optimized datacenters have become the essential substrate for automation, decision-making, and intelligent workflows at scale. Enterprise automation marks the rise of industrial intelligence: a world where continuous AI inference drives real economic productivity. To keep pace, businesses require not just access to AI infrastructure, but stability, transparency, and predictable economics in how inference capacity is delivered. A mature, reliable AI energy market will become the new backbone of enterprise growth.
I define Artificial Intelligence as the transference of electricity into productivity by automated means. We have seen a substantial increase in the refinement of AI automation, from simple chatbots to autonomous agents with reasoning capabilities. The underlying infrastructure is still an immature market of traditional cloud providers and new “Neo clouds.” But industrial intelligence cannot be sustained by a few cloud providers. An AI inference market is needed.
In early 2023, Nvidia’s H100 GPUs—priced between $25,000 and $40,000 per unit—sparked an infrastructure rush reminiscent of the early American oil boom. Investors and cloud providers, seeing a promising opportunity in projected rental rates of around $4 per GPU-hour and potential annual revenues exceeding $100,000 per GPU, quickly secured multi-year contracts, took out substantial loans, and expanded capacity to tap the surging demand for AI computing.
Yet, by early 2024, a rapid influx of GPU supply and heightened competition reshaped the landscape, echoing the volatility experienced by 1860s oil producers as they struggled to align new production with fluctuating demand. GPU rental prices dropped sharply: community-driven marketplaces like Vast.ai listed H100 PCIe GPUs for as low as $1.56 per hour, with platforms like RunPod offering comparable units between $1.99 and $2.69 per hour—figures far below initial forecasts. While this sudden correction strained newer or highly leveraged providers, it simultaneously opened the floodgates to high-performance computing, enabling startups, researchers, and smaller developers unprecedented access.
The GPU rental market involves providers purchasing GPU-based server systems—and offering them for rent on an hourly or monthly basis to customers who need powerful computing resources but don't want to make significant upfront investments. Customers typically include AI startups, researchers, and developers requiring substantial computing power for tasks like training or running AI models. Providers invest in GPUs expecting that high demand for computing power will lead to profitable rental rates. However, due to long manufacturing timelines and high upfront costs, these providers face financial risks if the supply of GPUs grows faster than customer demand, causing rental prices to fall. This price fluctuation impacts profitability, influencing future investment decisions in GPU-based infrastructure.
This unfolding scenario reflects a classic early-stage commodity market pattern: initial volatility followed by periods of overinvestment, price corrections, and eventual stabilization as supply chains mature and market expectations align with economic realities.
Despite the clear market signals, there's been no structured framework to explain this multi-layered dynamic for the AI market—so I built one: The AI Infrastructure Cycle.
This framework consists of three interlocking cycles, each with its own timeline, triggers, and economic implications:
The GPU/Hardware Cycle – driven by semiconductor manufacturing timelines and architectural breakthroughs.
The Datacenter Cycle – driven by GPU deployment, rental pricing, utilization rates, and ROI modeling.
The Intelligence Cycle – driven by AI model innovation, workload inflation, and shifts in inference demand.
Together, these cycles form a dynamic system—one that replaces the static assumptions of the old semiconductor era with a model that reflects how modern AI infrastructure actually evolves.

1. GPU Cycle (Hardware Layer)
Perhaps the biggest disconnect in this cycle right now is the traditional semiconductor lifecycle and the reality of the evolution of AI centric compute.
For decades, the semiconductor industry followed a relatively stable cadence shaped by Moore’s Law and hardware lifecycles measured in five- to seven-year intervals. In this traditional model, GPUs were treated as interchangeable compute accelerators or consumer graphics cards, purchased as capital assets and depreciated slowly over time. Hardware innovation was decoupled from software development, and infrastructure buyers—from enterprises to hyperscalers—could reasonably expect a GPU to remain economically useful for most of a decade.
NVIDIA has shattered this paradigm. Once a manufacturer of graphics cards, the company has evolved into a vertically integrated AI infrastructure platform—delivering not just GPUs, but a tightly coupled stack that includes NVLink interconnects, CUDA software, TensorRT inference optimizations, and end-to-end orchestration through AI OS releases. The GPU is no longer a commodity chip. It is now a full-stack, high-margin system node built to serve the lifecycles of AI workloads—especially large language models and agentic inference. CUDA makes it possible to rapidly support new models without retooling infrastructure, and NVLink enables memory architectures that treat a rack of GPUs as one supercomputer. NVIDIA's Blackwell and Hopper architectures are released on 12–18 month cycles, with integrated hardware-software advances that obsolete previous units economically—well before the silicon itself wears out. This shift renders the traditional semiconductor lifecycle obsolete for AI, and forces cloud providers to align their economic and technical planning with NVIDIA’s cadence, not the depreciation schedules of legacy compute.

2. AI Cloud Cycle (Platform Layer)
But assets need a depreciation schedule and the reality is that financial models of every cloud provider would blow up in their face if they aligned it to Nvidia’s cadence.
Cloud providers have traditionally depreciated their server and networking hardware over extended periods to optimize capital expenditures. For instance, in 2022, Microsoft extended the useful life of its Azure servers and network equipment from four to six years, attributing this to software optimizations and improved technology, which was expected to save $3.7 billion in fiscal year 2023 alone. Similarly, AWS increased its server lifespan from four to five years and networking gear from five to six years in early 2022, adding an extra $900 million to its Q1 2024 profit due to lower depreciation expenses. These adjustments were based on the belief that hardware could remain economically viable for longer periods, aligning with the slower pace of technological advancements at the time.
However, the rapid evolution of AI technologies has prompted a reevaluation of these depreciation schedules. In AWS's Q4 2024 earnings call, CFO Brian Olsavsky announced that the company had completed a new "useful life study" and found that the pace of technological advancement in AI/ML was accelerating so fast that some of AWS's newer gear would become obsolete sooner than expected. As a result, starting January 2025, AWS reduced the lifespan of certain AI-focused infrastructure from six years back to five, leading to a $700 million reduction in operating profit for 2025.
Other cloud providers are facing similar pressures. Analysts estimate that if Google were to follow AWS's lead and shorten its depreciation schedules, it could see a $3.5 billion decrease in operating profit. Meta might experience an even more significant impact, with potential reductions exceeding $5 billion. These figures underscore the financial challenges posed by the need to keep pace with rapid AI hardware advancements. As a result, cloud providers must balance the benefits of deploying cutting-edge AI infrastructure with the financial implications of shorter hardware lifecycles.
NVIDIA is moving at a pace that no other semiconductor company can match, and this unique velocity gives it the power to both pressure and preserve the economics of cloud providers. At the hardware layer, its 12–18 month release cadence of Hopper (H100), Blackwell (B100/B200), and the upcoming Rubin architecture—renders legacy chips economically obsolete faster than traditional depreciation models can accommodate. Cloud providers that have amortized infrastructure over 5–6 years, as was standard across AWS, Microsoft Azure, and Google Cloud, now face internal contradictions: top-line AI demand depends on cutting-edge throughput, while back-office accounting is still tied to slow, linear capex recovery. Every new NVIDIA launch tightens the gap between performance expectations and accounting reality, especially as enterprise clients and startups prioritize compatibility with the latest AI models and token-serving speeds.
Yet what makes NVIDIA’s approach so potent is not just the pressure—it’s the relief. Through its CUDA software stack, NVIDIA enables legacy GPUs to remain operationally viable long after their generational peak. CUDA’s consistent backward compatibility means that chips like the A100 can continue running newer models with optimized kernels, supported by runtime tools like TensorRT, cuDNN, and vLLM. This dynamic—where NVIDIA compresses time at the hardware layer while expanding time through software—is a market force I call “The Squeeze and Release Model.” It allows NVIDIA to maintain control of the upgrade cycle while simultaneously enabling GPU cloud providers to preserve margin, resale value, and utilization across generations. No other chipmaker offers this level of architectural tempo combined with platform stability, and this tension between acceleration and continuity is exactly what keeps hyperscalers locked into the NVIDIA ecosystem.
A Model for Financial Stress Test of AI Cloud Providers
Given were in the early days of the GPU rental market, we need a model to financially stress test cloud providers.
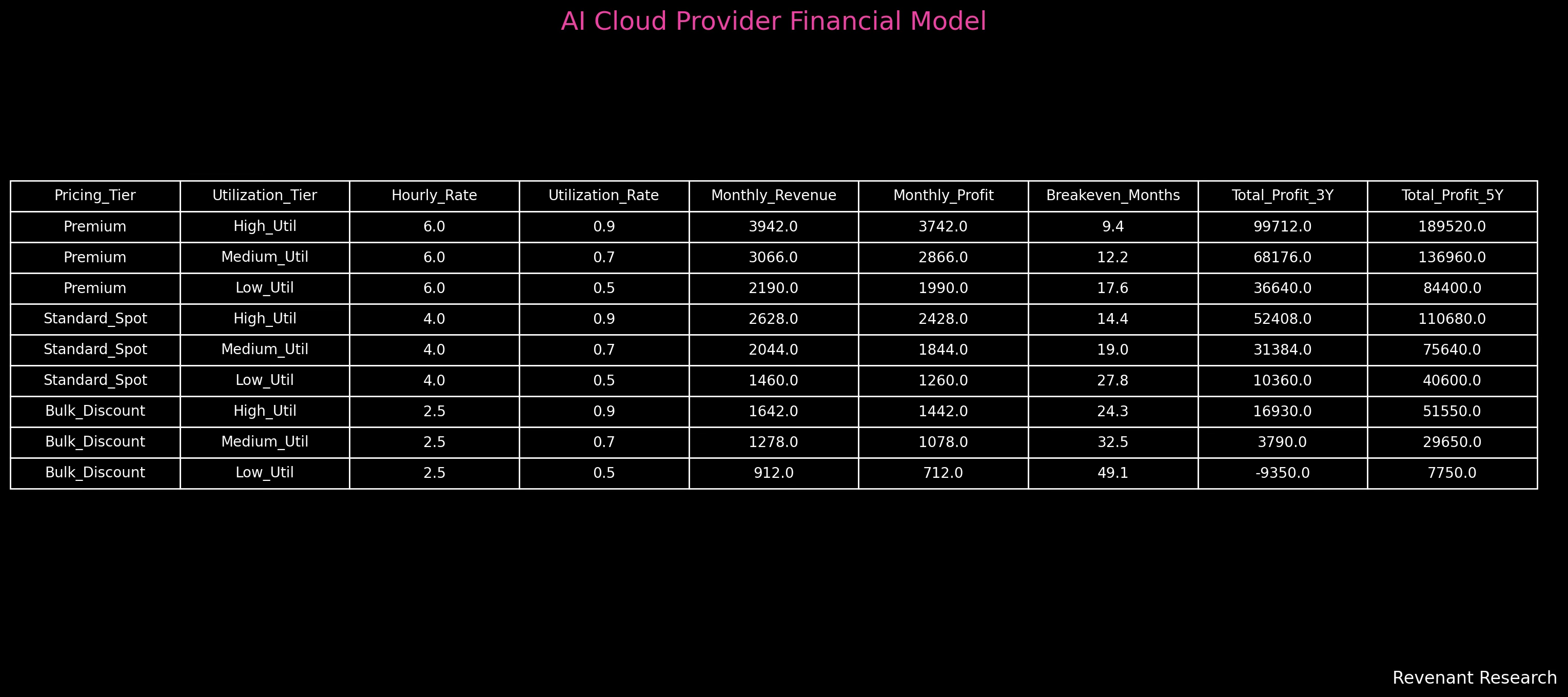
The Financial Model for AI Cloud Providers is a unit economics tool that evaluates breakeven timelines, profitability, and long-term ROI for GPU-based infrastructure. It is built around a set of core variables and assumptions that reflect the operational realities of running a GPU fleet in the AI economy. The model is structured as follows:
CapEx: the total upfront capital expenditure for each GPU system, including full-node cost (not just the card)
OpEx: the ongoing monthly operating expense per system, including power, cooling, and maintenance
Pricing Tiers: rental pricing categories that reflect customer segments or market volatility
Premium Pricing: high-demand enterprise rates
Standard Spot: typical spot market pricing
Bulk/Discount: low-margin, high-volume pricing
Hourly Rate: price charged per GPU-hour under each pricing tier
Utilization Tiers: percentage of the month each GPU is in active use
High Utilization: 90%
Medium Utilization: 70%
Low Utilization: 50%
Monthly Revenue: calculated as hourly rate × 730 hours × utilization rate
Monthly Profit: revenue minus OpEx
Breakeven Months: CapEx divided by monthly profit; the time needed to recover initial investment
Total Profit (3Y and 5Y): cumulative profit over 36 and 60 months, respectively, net of CapEx
The model allows cloud providers to simulate different pricing and fleet utilization strategies, test financial risk under market shifts, and quantify how fast hardware must pay for itself before obsolescence. It fits directly into the broader AI Infrastructure Cycle by exposing the financial pressure created by rapid GPU innovation cycles (12–18 months), fast-evolving model lifecycles (6–12 months), and the inflation of inference workloads. The model highlights the structural misalignment between traditional 5–6 year depreciation schedules and modern AI demand patterns, making it essential for cloud providers to adopt dynamic ROI forecasting tied to real model and workload behavior.
3. Model Cycle (Intelligence Layer)
Hardware deployment cycles must synchronize with the evolving demands of AI workloads, which fall into two distinct camps: training and inference. Training is spiky, capex-intensive, and tightly coupled to the development and launch of new foundational models. It tends to occur in bursts and is typically dominated by hyperscalers with specialized clusters. Inference, by contrast, is continuous, margin-sensitive, and fundamentally operational.
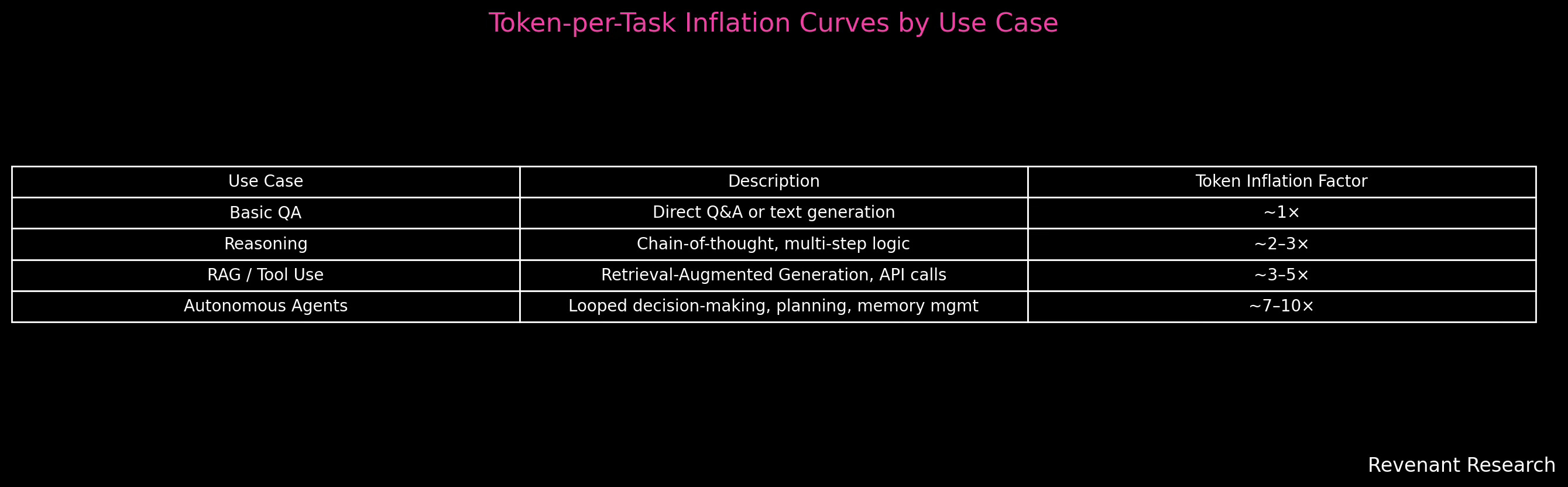
The emergence of high-value use cases, ranging from reasoning to tool calling, retrieval-augmented generation (RAG), and agentic workflows, has led to the rapid inflation of token-level workload demands. Simple Q&A or summarization tasks once had predictable token flows, but now a single logical request may involve recursive thought chains, memory calls, and multiple API interactions. A basic agent might be prompted to "analyze a document and schedule a meeting," yet internally decompose this into subtasks, retrieve external context, plan a schedule, call tools, and verify completion—all of which generates additional input/output operations. This behavior introduces what I define as the token-per-task inflation curve: a rising, non-linear trajectory that tracks how many tokens a model must process per completed task as complexity increases.
At the same time, advancements in model optimization are pushing token efficiency in the opposite direction. Techniques like quantization—reducing model precision from FP32 to INT8 or FP4—can cut memory and computation by 4–8× while maintaining performance. Mixture of Experts (MoE) models activate only a few internal “experts” per input, reducing the number of active parameters and thus FLOPs per token. These models use sparse activation, avoiding unnecessary computation, and pair well with software-side breakthroughs like FlashAttention and PagedAttention, which restructure attention mechanisms and memory layouts to squeeze more tokens per second out of each GPU. These optimizations drive down the cost per token across the stack, but they don’t resolve the fact that tokens per task is increasing, especially in enterprise-grade inference.
Each tier of model behavior introduces a new jump in this inflation curve. Basic LLMs responding to static prompts have token-to-task ratios close to 1×. Add Chain-of-Thought reasoning, and you often double or triple the output (~2–3×). Introduce RAG or tool usage, and token volume increases 3–5× per task. At the frontier, agentic models—capable of planning, decision-making, memory retrieval, and tool chaining—can inflate per-task token consumption by 7–10×. This inversion of economic assumptions breaks legacy logic: a well-optimized 8B model acting as an agent may be more expensive to serve than a 70B summarization model. Cloud providers can no longer use model size as a proxy for cost—they must model the inference topology, token inflation, and interaction loops.
The Dawn of the Industrial Intelligence Energy Market
We are entering the early stages of a fundamentally new kind of energy market that will power industrial intelligence. Enterprises are rapidly shifting to workflows automated through AI, making GPU-based computing a core operational necessity. This emerging market demands stability in service delivery, transparent and predictable pricing, and reliable access to specialized computing infrastructure. Just as industrial sectors historically required consistent and clearly priced energy to operate efficiently, tomorrow’s businesses will depend on a robust, transparent AI energy market to reliably fuel enterprise automation. Executives and investors who recognize and strategically adapt to this evolution will secure a critical competitive advantage, enabling sustained productivity and innovation. Those who fail to understand this new paradigm risk operational disruptions, financial uncertainty, and diminished market relevance.